Post by Fnu Suya
Data poisoning attacks are recognized as a top concern in the industry [1]. We focus on conventional indiscriminate data poisoning attacks, where an adversary injects a few crafted examples into the training data with the goal of increasing the test error of the induced model. Despite recent advances, indiscriminate poisoning attacks on large neural networks remain challenging [2]. In this work (to be presented at NeurIPS 2023), we revisit the vulnerabilities of more extensively studied linear models under indiscriminate poisoning attacks.
Understanding Vulnerabilities Across Different Datasets
We observed significant variations in the vulnerabilities of different datasets to poisoning attacks. Interestingly, certain datasets are robust against the best known attacks, even in the absence of any defensive measures.
The figure below illustrates the error rates (both before and after poisoning) of various datasets when assessed using the current best attacks with a 3% poisoning ratio under linear SVM model.
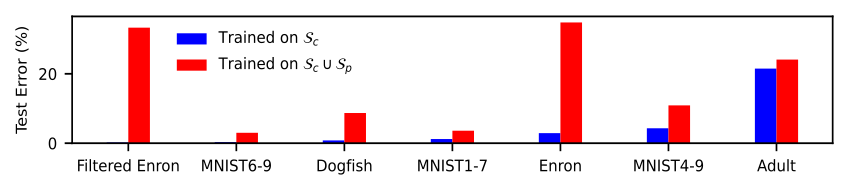
Here, $\mathcal{S}_c$ represents the original training set (before poisoning), and $\mathcal{S}_c \cup \mathcal{S}_p$ represents the combination of the original clean training set and the poisoning set generated by the current best attacks (the poisoned model). Different datasets exhibit widely varying vulnerability. For instance, datasets like MNIST 1-7 (with an error increase of <3% at a 3% poisoning ratio) display resilience to current best attacks even without any defensive mechanisms. This leads to an important question: Are datasets like MNIST 1-7 inherently robust to attacks, or are they merely resilient to current attack methods?
Why Some Datasets Resist Poisoning
To address this question, we conducted a series of theoretical analyses. Our findings indicate that ditributions, which are characterized by high class-wise separability (Sep) and low in-class variance (SD), as well as smaller sizes for the set containing all poisoning points (Size), inherently exhibit resistance to poisoning attacks.
Returning to the benchmark datasets, we observed a strong correlation between the identified metrics and the empirically observed vulnerabilities to current best attacks. This reaffirms our theoretical findings. Notably, we employed the ratios Sep/SD and Sep/Size for convenient comparison between datasets, as depicted in the results below:
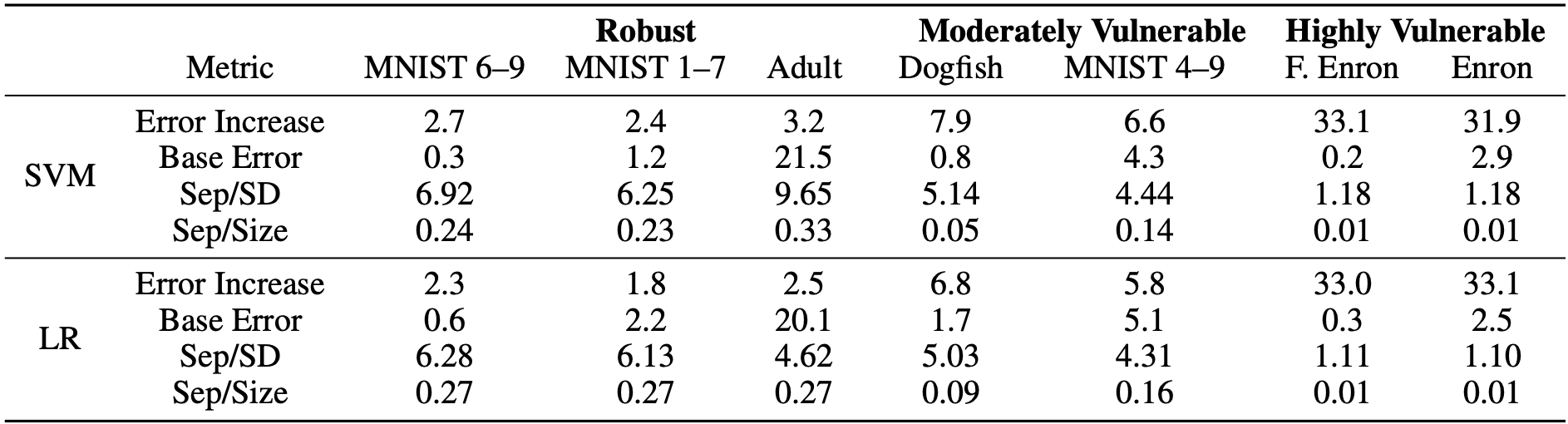
Datasets that are resistant to current attacks, like MNIST 1-7, exhibit larger Sep/SD and Sep/Size ratios. This suggests well-separated distributions with low variance and limited impact from poisoning points. Conversely, more vulnerable datasets, such as the spam email dataset Enron, display the opposite characteristics.
Implications
While explaining the variations in vulnerabilities across datasets is valuable, our overriding goal is to improve robustness as much as possible. Our primary finding suggests that dataset robustness against poisoning attacks can be enhanced by leveraging favorable distributional properties.
In preliminary experiments, we demonstrate that employing improved feature extractors, such as deep models trained for an extended number of epochs, can achieve this objective.
We trained various feature extractors on the complete CIFAR-10 dataset and fine-tuned them on data labeled “Truck” and “Ship” for a downstream binary classification task. We utilized a deeper model, ResNet-18, trained for X epochs and denoted these models as R-X. Additionally, we included a straightforward CNN model trained until full convergence (LeNet). This approach allowed us to obtain a diverse set of pretrained models representing different potential feature representations for the downstream training data.
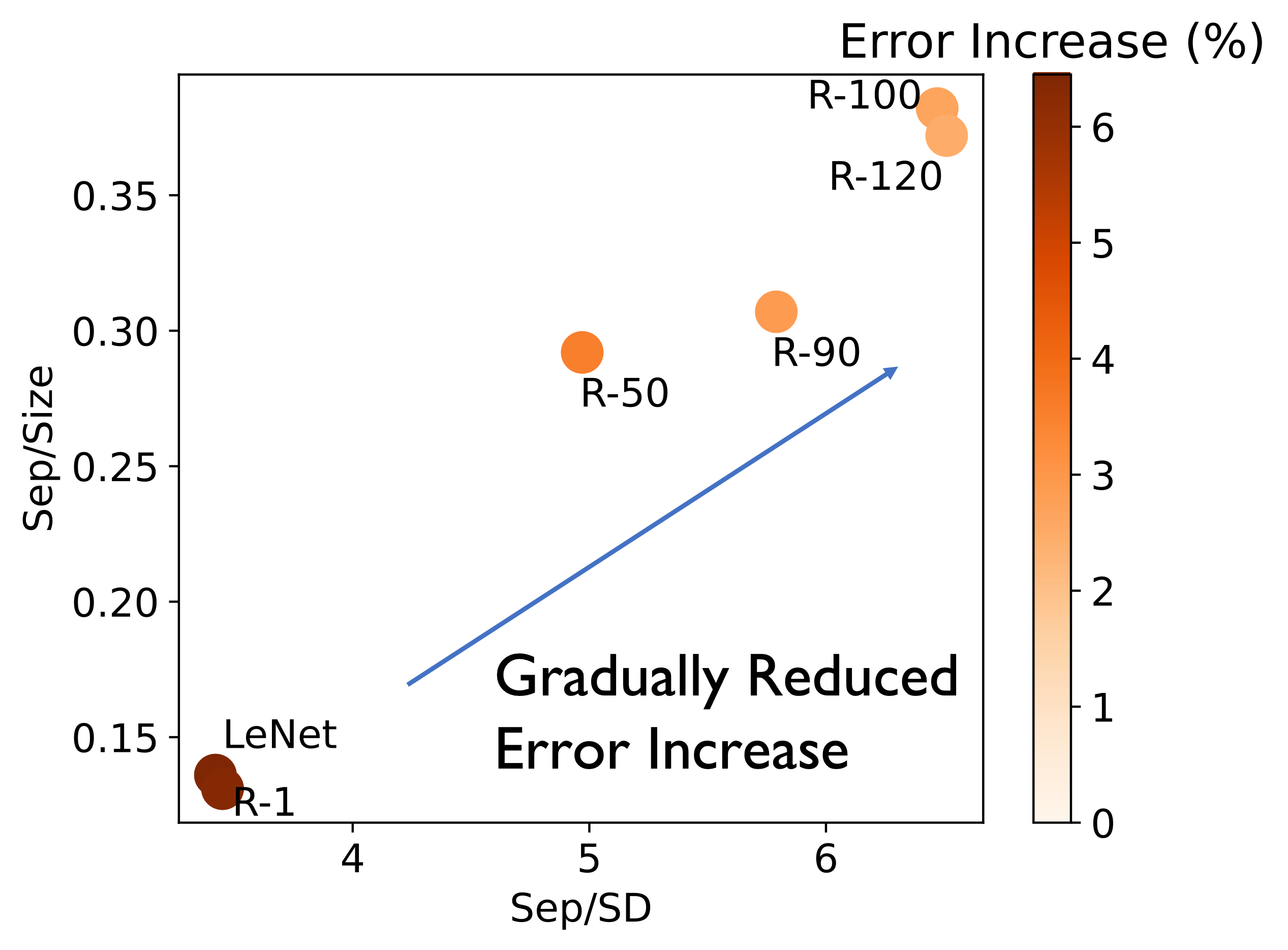
The figure above shows that as we utilize the ResNet model and train it for a sufficient number of epochs, the quality of the feature representation improves, subsequently enhancing the robustness of downstream models against poisoning attacks. These preliminary findings highlight the exciting potential for future research aimed at leveraging enhanced features to bolster resilience against poisoning attacks. This serves as a strong motivation for further in-depth exploration in this direction.
Paper
Fnu Suya, Xiao Zhang, Yuan Tian, David Evans. What Distributions are Robust to Indiscriminate Poisoning Attacks for Linear Learners?. In Neural Information Processing Systems (NeurIPS). New Orleans, 10–17 December 2023. [arXiv]